Навигационная цепочка "где я сейчас?" - траектория от главной до текущей страницы сайта. Breadcrumbs.
Передовица (меню разделов)
⇓
Hardware
⇓
ДЗУ (дисководы и их контроллеры)
⇓
Исследование КНГМД 140
⇓
Ошибки дискет под микроскопом
Ошибки дискет под микроскопом
В конечном итоге мне удалось сделать свой контроллер, который выполняет чтение и запись агатовских дискет. Однако возникла следующая проблема, решение которой для меня пока не очевидно.
Суть такова: при многократном перечитывании дорожки неуверенно читающийся сектор иногда удаётся всё же прочитать. Поэтому программное обеспечение моего контроллера выполняет более сотни попыток чтения, постоянно чередуя параметры: положение головок, таблицы секвенсора, анализируя каждый вариант в течение нескольких оборотов дискеты. Положение головок чередуется между нулевым и незначительным смещением на разное расстояние в разные стороны. Но в результате многократных попыток иногда возникают ситуации, когда "шум" (т.е. неуверенное чтения отдельных байт и бит) приводит к такой модификации данных, которая подходит к имеющейся контрольной сумме, но не является верной. Напомню, что формат предполагает один байт контрольной суммы, вычисляемый как "исключающее ИЛИ", для $156 байт данных.
При проектировании моста 840кб подобного эффекта отмечено практически не было (пара секторов на сотни обработанных дискет). Попытки повторного чтения на одном и том же дисководе крайне редко позволяли прочитать сбойный сектор (3-5 оборотов/попыток ещё имели смысл, но не больше).
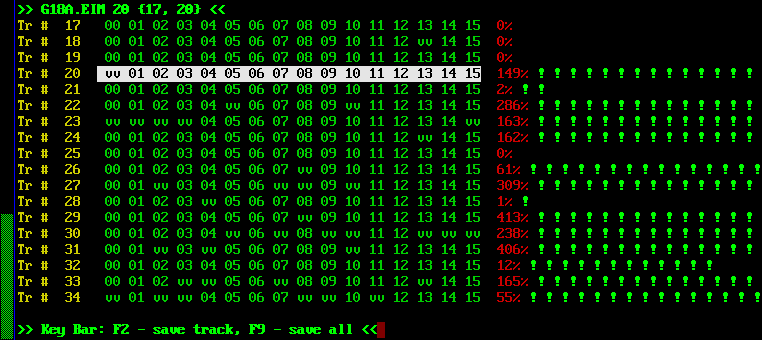
| Особенно отличившаяся (в смысле вариантов чтений) дискета. Сектора, отмеченные как "vv", прочитались несколько раз по разному. Но какой-то из вариантов повторялся существенно чаще других и программа выбрала нужные варианты самостоятельно. Причем эти варианты набирались очень быстро - здесь большинство секторов прочитано не больше 120-180 раз (на плохих дискетах приходится перечитывать до 800 раз). |
Для борьбы с этим эффектом на 140кб, в настоящее время, применяется следующий алгоритм: сектор должен прочитаться не меньше двух раз подряд (когда все сектора на дорожке достигают этого значения - дорожка считается считанной и происходит переход к следующей), между попытками не должно быть успешных чтений, результат которых (декодированные данные) не совпадают нынешним. Если сектор успешно (и однозначно) прочитан более девяти раз, его анализ вообще прекращается.
На практике это выглядит так: хорошая дорожка будет прочитана приблизительно за 2-3 оборота. Плохая дорожка сразу выявляет своих лидеров (которые быстро набирают девять успешных попыток чтения) и аутсайдеров (их счётчики успеха прыгают: 0... 1... 0... 1... 2, ... К этому моменту лидеры уже набирают девятку, а число пройденных оборотов превышает несколько десятков).
Это не очень удачный алгоритм. Думаю, наилучшим решением был бы статистический анализ: многократное чтение, после которого верным считается тот вариант результата, который встречается чаще (хотя и этот вариант неидеален: при наличии стабильной повторяющейся ошибки шум может привести к периодическому совпадению CRC, но ошибка-то (если она стабильна !) никуда не денется). Но нынешняя реализация менее требовательна к памяти и проще алгоритмически, а статистический подход реализован в RawEdit140 - отдельном редакторе EIM-образов.
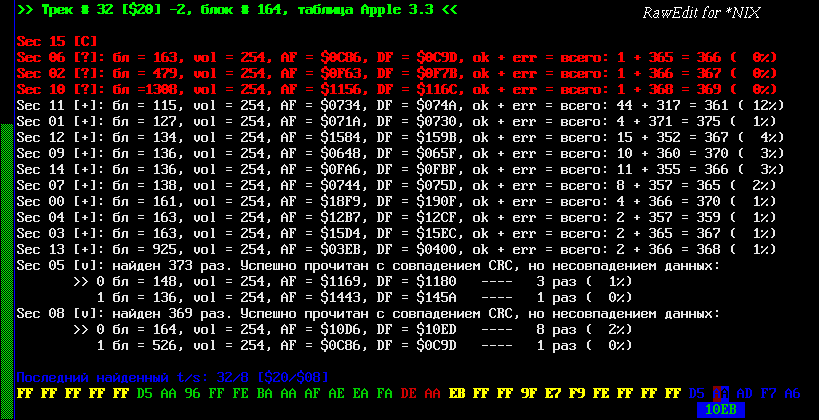
| Зелёная строка вверху - информация о выводимом в нижней строке блоке: трек 32, смещение -2 (в терминах "КОРРЕКТОРА СМЕЩЕНИЯ"), программа секвенсора - "Apple 3.3". Дальше информация о найденных секторах (сводная, по всем блокам данного трека). Красный цвет - ошибки, сектор 15 - "C" - ошибка CRC (т.е. ни одного успешного чтения), сектора 6, 2, 10 - "?" - неуверенное чтение: меньше одной успешной попытки на 256 найденных полей адреса, сектора 5 и 8 - "v" - найдены разные версии, но программа смогла автоматически выбрать наиболее вероятную, остальные сектора прочитались без вопросов, хотя и далеко не с первой попытки. Треки 29-34 всегда читаются неуверенно, этот - 32-й - так что полученный результат - почти закономерность. Возможно, если бы у этих дисководов и/или контроллеров использовалась предкомпенсация записи - ситуация могла быть лучше. |
Однако практика показала, что после введения подобной логики отбора (до этого использовалось чтение до первого совпадения CRC), образы, читаемые с одной и той же дискеты, отличаются только наличием или отсутствием некоторых секторов (Я уже не знаю - сколько ещё дать попыток, чтобы точно прочитывалось всё. С другой стороны - рост попыток увеличивает вероятность ошибочного чтения с совпадением CRC). Несовпадений данных в одних и тех же секторах пока не случалось (хотя, конечно, статистика пока маловата).
Ещё одна мысль: ориентироваться не только на CRC, но и ограничения GCR-кодирования: оно предполагает очень конечный набор значений хранимых на диске байт ($96, $97, $9A, $9B...). Эта мысль была реализована, но на первом же диске был найден сектор, который содержал фрагмент из 18 байт, менявшийся от попытки к попытке так удачно, что не выходил за GRC-ограничения и, к тому же, версии фрагмента давали идентичную CRC ! Причем было хорошо видно, что ошибка возникает из-за потери в первом байте шестого бита (равного нулю), но не было ясно, почему эта ошибка в итоге компенсируется (как бы из ниоткуда возникали несколько единиц в конце ("??????")). Взгляните сами (первый фрагмент, вероятно, правильный, второй - нет):
B5 BE DD FC F2 DE 9B D6 F6 F2 DE CB FC E9 EC E6 F9 FA - правильный
EB FB EF E7 96 F4 DE B7 B7 96 F6 BF CE 9E CE DF DF FD - неправильный
Если разложить побитно:
b5 be dd
x-- --- x-- --- x-- --- x-- --- x-- --- x-- --- x-- --- x-- --- x-- --- x-- --- x-- --- \
1011010110111110110111011111110011110010110111101001101111010110111101101111001011011110 ----\
11101011 11111011 111011111110011110010110111101001101111010110111101101111001011011110 ----/
x-- --- x-- --- x-- --- x-- --- x-- --- x-- --- x-- --- x-- --- x-- --- x-- --- x-- - /
eb fb ef
^-- пропущен ноль - исходная ошибка
v--- тут вдруг всё совсем разошлось
f9 fa здесь последовательность
\ x-- --- x-- --- x-- --- x-- --- x-- --- x-- --- x-- --- вновь совпала
-----\ 11001011111111001110100111101100111001101111100111111010??????? 1101 1100 1110 0111
-----/ 110 10111111110011101001111011001110 11011111 1101111111111101 1101 1100 1110 0111
/ -- x-- --- x-- --- x-- --- x-- --- x-- --- x-- --- x-- ---
df fd
Не забывайте о том, что контроллер будет пропускать нули, если они приходятся на начало байта.
А также о том, что CRC вычисляется только после следующего табличного преобразования:
recod: Array[$96..$ff] of Byte = (
$00,$01, $--,$--,$02,$03, $--,$04,$05,$06,
$--,$--,$--,$--, $--,$--,$07,$08, $--,$--,$--,$09, $0A,$0B,$0C,$0D,
$--,$--,$0E,$0F, $10,$11,$12,$13, $--,$14,$15,$16, $17,$18,$19,$1A,
$--,$--,$--,$--, $--,$--,$--,$--, $--,$--,$--,$1B, $--,$1C,$1D,$1E,
$--,$--,$--,$1F, $--,$--,$20,$21, $--,$22,$23,$24, $25,$26,$27,$28,
$--,$--,$--,$--, $--,$29,$2A,$2B, $--,$2C,$2D,$2E, $2F,$30,$31,$32,
$--,$--,$33,$34, $35,$36,$37,$38, $--,$39,$3A,$3B, $3C,$3D,$3E,$3F);
"$--" - запрещённые комбинации (не соответствующие GCR). Контрольная сумма правильного и неправильного фрагментов - $0B.
И всё же, контроль соответствия ограничениям GCR нельзя назвать совсем бесполезным: на последних дорожках опытных дискет (записанных в начале 90-х) на этом тесте срезается до половины секторов.
Ещё одна идея, родившаяся после приличного количества обработанных дискет: сопоставлять качество чтения не единственного сектора, а всей дорожки. Т.е. если дорожки, прочитаные разными дисководами, имеют несовпадающие данные, то считать верным тот вариант, который находился на наиболее успешном (по статистике чтения других секторов) варианте дорожки.
Видеоролик о том, как это работает:
Первый блин - комом, конечно (это я про видео), но если отбросить форму - содержание вроде неплохое...