Навигационная цепочка "где я сейчас?" - траектория от главной до текущей страницы сайта. Breadcrumbs.
Передовица (меню разделов)
⇓
Документы
⇓
ИиО
⇓
Создание текстовых файлов (баз данных) на ПЭВМ Агат
Создание текстовых файлов (баз данных) на ПЭВМ Агат (N2/1998)
Р. К. Спивак, преподаватель программирования УВК N16, Москва. Группа сайта просит вас связаться с нами! (ЗАЧЕМ ЭТО?)
Системы управления базами данных (СУБД) - это специальные программы, обеспечивающие ввод, хранение, поиск и выдачу по запросу пользователя нужных записей.
Любая база данных должна быть:
1) полной;
2) правильно организованной;
3) всегда соответствующей текущему моменту;
4) удобной для пользования.
ЭВМ представляет собой идеальное средство для организации, сбора и обработки данных.
Структура файла
Часто в программе обрабатывается большой объём информации, которую удобно объединять в наборы данных и хранить вне оперативной памяти компьютера на дискетах. Такие наборы данных называются файлами. Файл состоит из записей, каждая из которых может содержать одно или несколько значений данных. Значение каждого элемента информационной записи называют полем.
Доступ к файлу
Поиск требуемых записей в файле может быть организован двумя способами:
1) последовательный доступ;
2) прямой, или произвольный доступ.
Последовательный доступ. Поиск производится проверкой по очереди каждой записи с начала файла до тех пор, пока не будет найдена требуемая. В последовательно организованном файле длина записи зависит от величины каждого поля.
Преимущества последовательного доступа:
1) прост для программирования;
2) требуется меньше памяти на временных носителях.
Недостатки последовательного доступа:
1) может понадобиться значительное время для поиска записи, находящейся в конце длинного файла;
2) обновление файла трудноосуществимо.
Произвольный, или прямой, доступ. Позволяет обращаться к записям по их номерам в любом порядке.
Преимущества прямого доступа:
1) легко поддаётся обновлению;
2) поиск любых записей осуществляется с одинаковой скоростью.
Недостатки прямого доступа:
1) сложнее программируется;
2) обычно требует больше места на диске, чем для последовательного файла.
Чтобы считать из файла конкретное поле записи, программа должна открыть этот файл, найти соответствующую запись, переслать её с диска в оперативную память и, наконец, выделить требуемую информацию в виде значения переменной. Запись данных в файл производится аналогичным способом с той разницей, что в этом случае значения пересылаются программой из динамической памяти на диск.
Организация баз данных сводится к написанию программ, обеспечивающих хранение, пополнение и корректировку информации на дискете. Ниже дан пример программы, создающей текстовый файл последовательной структуры и записывающей в него данные, вводимые с клавиатуры.
10 INPUT W$ 20 INPUT A$ 30 PRINT CHR$ (4); "OPEN"; W$ 40 PRINT CHR$ (4); "WRITE"; W$ 50 PRINT A$ 60 PRINT CHR$(4); "CLOSE"; W$
Оператор INPUT в строке 10 в начале работы программы запрашивает имя создаваемого файла. Следующий оператор INPUT в строке 20 обеспечивает ввод данных с клавиатуры. Эта информация запоминается в символьной переменной A$. Операторы в строках 30 и 40 открывают текстовый файл с именем, указанным в переменной W$, и переводят его в режим записи, а оператор в строке 50 записывает содержимое переменной A$ в созданный файл.
В программах оператор PRINT обычно используется для вывода информации на экран, т.е. на внешнее устройство. Если же мы работаем с СУБД, то внешним устройством является диск. Поэтому здесь тоже используется оператор PRINT. На диске при работе указанной программы появится новый файл типа Т (текстовый).
При разработке реальной программы СУБД удобно подготовить типовые модули, реализующие отдельные операции работы с базой данных. Ниже приведены три программы для создания файла, дозаписи в него информации и чтения из файла.
1. Создание файла. В этой программе создаётся файл с именем, которое вводится пользователем в переменную W$, и в качестве первой записи в него помещается слово «МАХ».
10 A$="MAX" 20 INPUT W$ 30 PRINT CHR$(4); "OPEN"; W$ 40 PRINT CHR$(4); "WRITE"; W$ 50 PRINT A$ 60 PRINT CHR$(4); "CLOSE"; W$
2. Дозапись в файл слова «MIX». В этой программе производится дозапись в файл слова «МIХ» на первое свободное место. Если и в программе 1, и в программе 2 было введено одно и то же имя файла, то на первом месте в нем окажется слово «МАХ», а на втором - слово «MIX».
10 A$="MIX" 15 INPUT W$ 20 PRINT CHR$(4); "APPEND"; W$ 30 PRINT CHR$(4); "WRITE"; W$ 40 PRINT A$ 50 PRINT CHR$(4); "CLOSE"; W$
3. Чтение из файла.
5 INPUT W$ 10 PRINT CHR$(4); "OPEN"; W$ 20 PRINT CHR$(4); "READ"; W$ 30 INPUT A$ 40 INPUT B$ 50 PRINT CHR$(4); "CLOSE"; W$ 60 PRINT A$ 70 PRINT B$
Файл открывается для чтения в строках 10 и 20, а само чтение осуществляется в строках 30 и 40.
Оператор INPUT обычно служит для ввода информации с клавиатуры, которая в этом случае является внешним устройством. В СУБД диск - это тоже внешнее устройство, с которого вводится информация в память машины.
Если в программах 1, 2 и 3 было использовано одно и то же имя файла, то переменной A$ будет присвоено строковое значение «МАХ», а переменной В$ - значение «MIX». В строках 60 и 70 осуществляется их вывод на экран.
Пример задачи, которая используется при изучении баз данных: создать СУБД, представляющую собой телефонную книгу с фамилиями и телефонами. Такая программа должна обеспечивать:
1) создание базы данных;
2) дополнение её новыми записями;
3) сортировку фамилий в алфавитном порядке;
4) считывание записей с диска в память ПЭВМ;
5) выбор по запросу пользователя конкретного абонента
Структуру программы покажем в виде блок-схем.
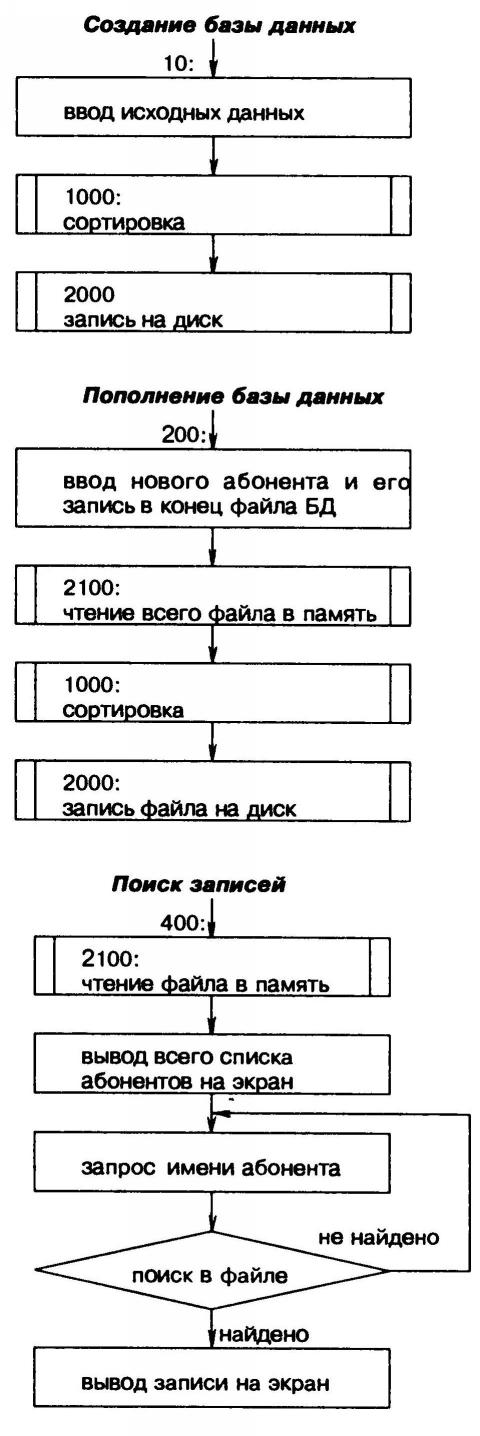
Листинг полученной в результате программы выглядит следующим образом:
10 DIM A$(40) 20 DATA "Иванов 253 7889", "Сидоров 729 3823", "Кириллов 421 2795" 30 FOR I = 1 ТО 3 40 READ A$(I) 50 NEXT I 70 GOSUB 1000 80 GOSUB 2000 90 END 200 INPUT "введите имя файла"; W$ 210 INPUT "введите нового абонента"; B$ 220 PRINT CHR$ (4); "APPEND"; W$ 230 PRINT CHR$ (4); "WRITE"; W$ 240 PRINT B$ 250 PRINT CHR$ (4);"CLOSE"; W$ 260 DIM A$(40) 270 GOSUB 2100 280 GOSUB 1000 290 GOSUB 2000 300 END 400 DIM A(40) 410 GOSUB 2100 420 FOR I = 1 TO N 430 PRINT A$(I) 440 NEXT I 450 PRINT "введите фамилию абонента" 460 INPUT B$ 465 Y = LEN(B$) 466 PRINT Y 470 FOR I = 1 TO N 480 IF LEFT$ (A$(I),Y) = B$ THEN PRINT A$(I): END 490 NEXT I 500 PRINT "абонент не найден": GOTO 450 1000 INPUT "введите кол-во абонентов"; N 1005 PRINT "***" 1010 FOR I = 2 TO N 1020 FOR J = 1 TO I 1030 IF ASC(LEFT$(A$(I),1)) < ASC(LEFT$(A$(J),1)) THEN B$=A$(I) : A$(I)=A$(J):A$(J)=B$ 1040 NEXT J 1050 NEXT I 1051 FOR I = 1 TO N 1052 PRINT A$(I): NEXT I 1060 RETURN 2000 INPUT "введите имя файла"; W$ 2005 INPUT "введите кол-во абонентов"; N 2010 PRINT CHR$(4); "OPEN"; W$ 2020 PRINT CHR$(4); "WRITE"; W$ 2030 FOR I = 1 TO N 2040 PRINT A$(I) 2050 NEXT I 2060 PRINT CHR$ (4); "CLOSE"; W$ 2070 RETURN 2100 INPUT "введите имя файла"; W$ 2110 INPUT "введите кол-во абонентов"; N 2120 PRINT CHR$ (4); "OPEN"; W$ 2125 PRINT CHR$ (4); "READ"; W$ 2130 FOR I = 1 TO N 2140 INPUT A$(I): ONERR GOTO 2160 2150 NEXT I 2160 PRINT CHR$ (4);"CLOSE"; W$ 2170 RETURN
Комментарий редактора
Приведённый в статье листинг программы «Телефонная книга» хотя в достаточной мере пригоден (и полезен) для демонстрации работы СУБД в учебных целях, однако обладает рядом крупных недостатков с точки зрения структуры алгоритма и идеологии построения баз данных.
Прежде всего, крайне нежелательной является компоновка программы в виде набора объединённых в одном листинге отдельных индивидуальных модулей, каждый из которых завершается командой END (так что внутри одного и того же листинга оказывается несколько операторов END), а вызов того или иного модуля на исполнение производится командой RUN с явным указанием номера строки (в вышеприведённом примере - RUN 10, RUN 200 или RUN 400). В целом модульное построение программы можно считать правильным решением с точки зрения структурности программирования, но при этом необходимо реализовать некий основной модуль (скажем, в виде меню), начинающий работать сразу после запуска программы, позволяющий пользователю выбрать требуемую операцию с базой данных и запускающий соответствующий модуль, оформленный в виде подпрограммы (с командой RETURN в качестве последней строки, а не END).
Второй недостаток заключается в не совсем правильной идеологии обработки файла базы данных (это вызов после дописывания в конец файла сведений о новом абоненте операций чтения всего этого файла в память, сортировки по алфавиту и перезаписи его на диск). Чтение, сортировка и перезапись в отсортированном виде занимают лишнее время, но последующий поиск записи (если брать среднее время поиска, рассчитанное по замерам для нескольких примеров фамилий абонентов) такая сортировка не ускоряет. В принципе, возможно увеличение скорости поиска путём оптимизации размещения записей в файле базы данных по их нужности (т.е. по частоте встречаемости запросов пользователей), если удаётся отследить каким-либо способом этот параметр. (Например, при построении и ведении базы данных медицинского характера имеет смысл пересортировать записи так, чтобы в начале файла оказывались сведения о наиболее часто встречающихся заболеваниях, а ближе к концу файла - о сравнительно редких болезнях). При использовании прямого доступа к файлу упорядоченность записей в нём ещё даёт определённые преимущества в скорости доступа (скажем, при поиске записей, начинающихся на «Я», в отсортированном по алфавиту списке эту операцию можно вести не с начала файла), но для последовательного доступа такая сортировка практически не требуется. Примером реальной СУБД может служить DBASE, где новые записи дописываются в конец файла, а сортировка производится только в оперативной памяти при необходимости (главным образом для вывода на экран или принтер отобранной по заданному шаблону поиска выборки записей).
Третий недостаток приведённой в статье программы - это отсутствие возможности удаления записей из базы данных (как ни странно, операция удаления здесь вообще не рассматривается, хотя является непременным атрибутом любой реальной СУБД).
И наконец, очень неудобно то, что практически каждая операция с файлом базы данных сопровождается в программе запросом у пользователя количества записей в файле (отслеживать которое пользователю ещё труднее, если учесть, что в процессе работы с СУБД оно может изменяться). При использовании прямого доступа к файлу или при работе с версиями Бейсика, допускающими при последовательном доступе запоминание текущей позиции в файле (так что можно, прервав чтение из файла, впоследствии продолжить его не с первой записи, а с того места, где оно было прекращено перед этим), лучше всего хранить количество записей в начале самого файла базы данных. Если же имеющийся Бейсик не допускает подобных «вольностей» (как, похоже, и обстоит дело на ПЭВМ «Агат»), можно выйти из положения, отведя для хранения количества записей отдельный файл (скажем, с именем, отличающимся от имени соответствующего ему файла базы данных заранее оговорённым символом, допустимым в данной операционной системе, например «!»). При запуске программы СУБД она прежде всего должна считать количество записей в переменную N, затем использовать её во время работы (изменяя её значение при добавлении/удалении записей), а перед окончанием работы записать в тот же файл поверх прежнего значения для хранения до следующего рабочего сеанса.
Доработку программы с целью устранения этих и других более мелких недочётов (например, реализацию сортировки по нескольким первым буквам, а не по только одной) редакция оставляет читателям; эта работа также может быть поручена учащимся в качестве самостоятельного задания.
Более подробную информацию о создании баз данных средствами Бейсика «Агат» (в том числе о реализации прямого доступа к содержащимся в файле записям) можно найти в книге: Мымрин М. П. Конструкция, применение, программирование и ремонт ПЭВМ АГАТ. М.: Машиностроение, 1990.